Decision Tree vs Decision Table: When to Use Each
Published on: 2026-04-11 18:50:16
Decision tree vs decision table
A decision tree and a decision table can represent the same decision logic. The difference is how that logic is organized, read, and maintained.
A decision tree models decisions as branches. Each node splits the path based on a condition. You follow one path until you reach an outcome. A decision table models decisions as rows and columns. Each row defines a rule combination and the result that follows.
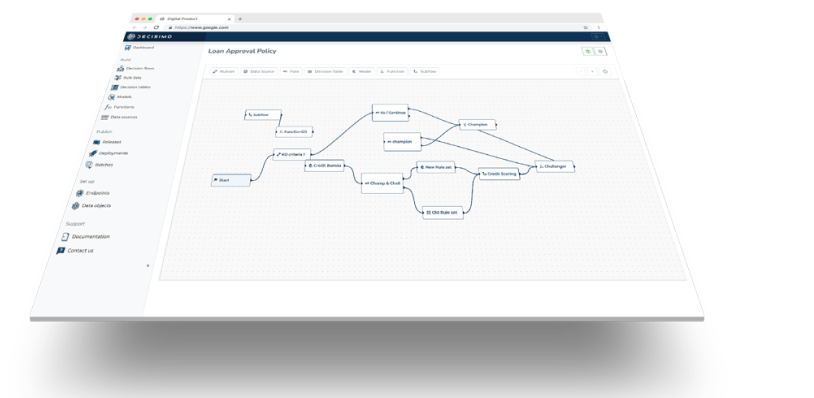
You can translate a decision table into a tree. You can also translate a tree into a table. In practice, the choice changes how easy the logic is to understand, test, and extend.
What a decision table is good for
Decision tables work well when you need a compact way to express repeated combinations of conditions and outcomes. They are strong at segmentation. They are also useful as a lookup table or an actuarial table, where the same variables combine into many possible outcomes.
That structure is useful when the decision depends on a defined set of attributes such as age band, income band, risk tier, region, product type, or customer segment. Each row is a rule. Each rule is explicit. That makes the table easy to audit.
Why decision tables are strong for segmentation
Segmentation is where decision tables shine. If your logic is based on groups, buckets, or fixed combinations, a table keeps the rules visible. You can scan the rows and see exactly which combination leads to which result.
This is why actuarial teams often prefer table-style logic. The structure fits the problem. The output is a clean mapping from inputs to outcomes, with less visual noise than a branched tree.
- Good for fixed condition sets
- Good for lookups and bucketed outcomes
- Good for audit trails and rule review
- Good when you want all combinations listed explicitly
Where decision tables become heavy
Decision tables get harder to manage as the number of conditions grows. Every new column adds another dimension. If the rule set expands quickly, the table can become wide and dense.
That is especially true when the logic is not naturally flat. If one condition depends on another, or if some branches split only after several earlier checks, the table starts to grow fast. In those cases, the table may stay correct but become hard to work with.
This is the main trade-off. A table is clear when the logic is stable and segmented. It gets complex when the rule space multiplies.
What a decision tree is good for
Decision trees are strong when you want to show how a decision unfolds step by step. They are especially useful for visual segmentation. The branching structure makes it easy to explain the path from input to outcome.
That visual form helps teams reason about the logic. Product, risk, operations, and compliance teams can see the sequence of checks without reading a dense matrix.
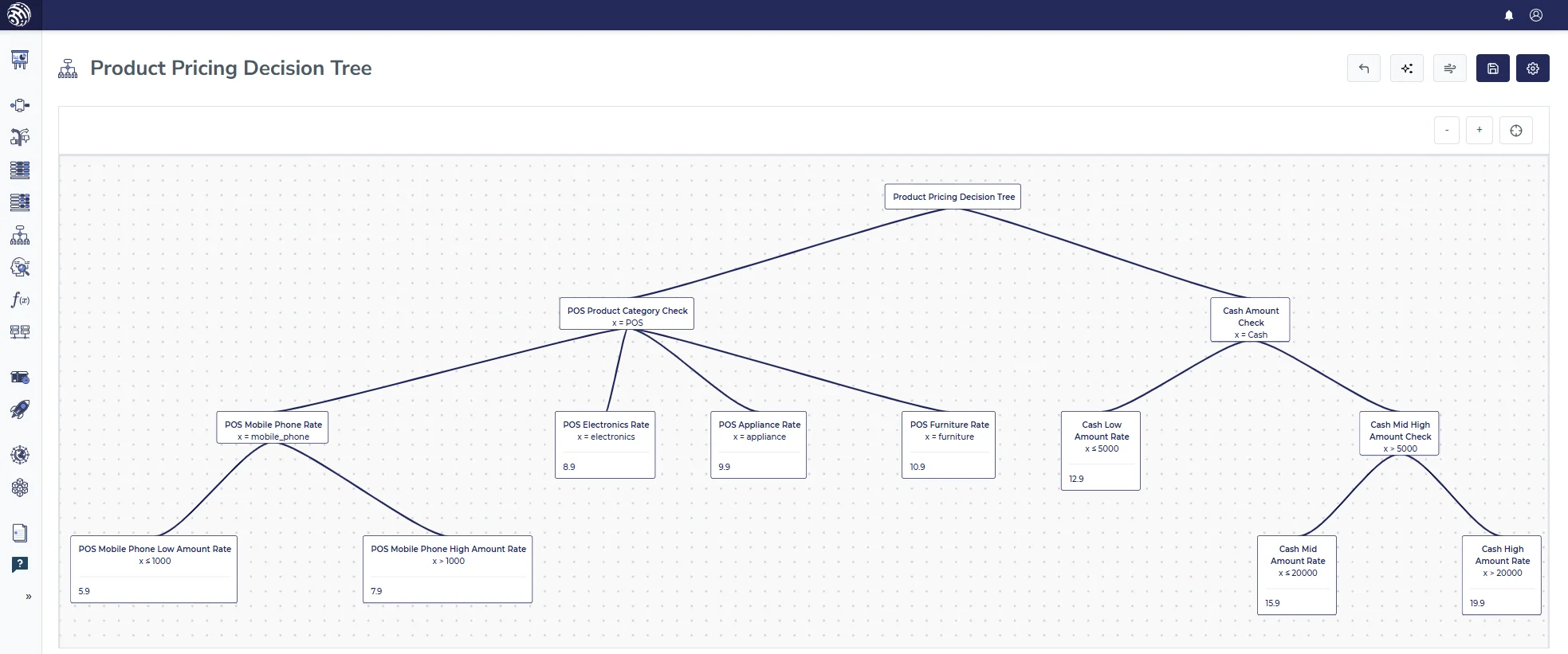
Why decision trees work for visual reasoning
A tree is easier to discuss when the question is, “What happens first?” or “What do we check next?” The path tells the story. Each split reduces the problem until the final decision appears.
This is useful when the decision logic has natural hierarchy. For example, a system might first check eligibility, then fraud risk, then affordability, then pricing. That structure is easier to read as a tree than as a table.
- Good for step-by-step logic
- Good for explaining decision paths
- Good when conditions are hierarchical
- Good when teams need a visual model
Where decision trees become awkward
Decision trees become messy when branches split in uneven ways. If one branch has three more checks and another branch has only one, the tree stops looking balanced. That is not a problem for logic. It is a problem for readability.
When branches split in a weird way, the tree can become harder to maintain than a table. Each new splitting condition may add another column if you try to translate it into a decision table. That makes the table wider and more complex, especially when the tree has many irregular paths.
This is the key point: irregular branching does not break the logic, but it can make the equivalent table harder to manage. The shape of the tree matters.
Can you translate one into the other?
Yes. In principle, any decision table can be represented as a tree, and any decision tree can be flattened into a table. The issue is not whether translation is possible. The issue is whether the translated form remains readable.
A clean table with a small number of conditions can become a clear tree. A clean tree with a predictable branch structure can become a useful table. But once the tree has uneven depth or repeated conditions on different branches, the flattened table may become large and awkward.
So the right question is not “Which one is more powerful?” The right question is “Which one matches the shape of the decision logic?”
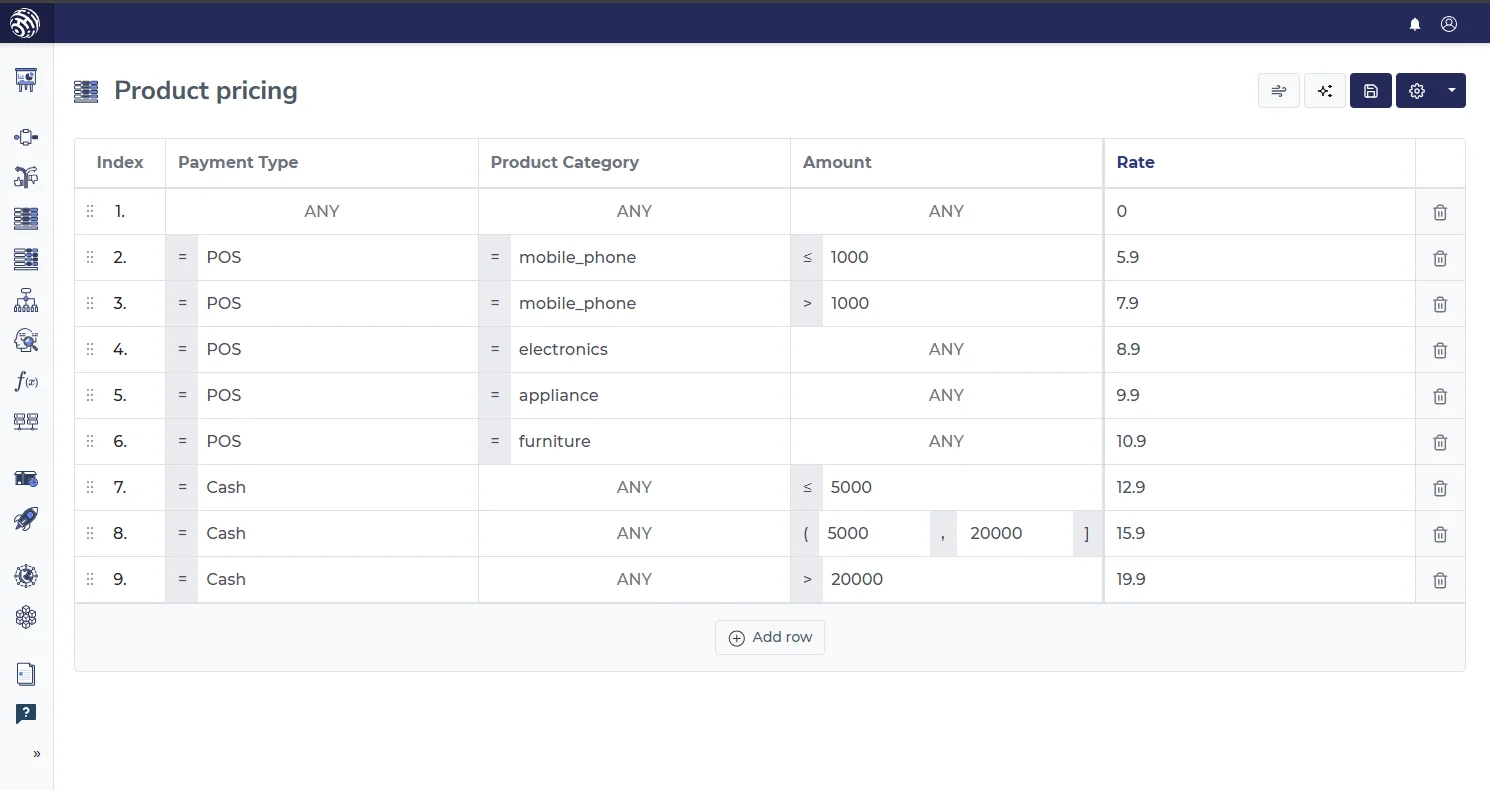
How to choose between them
Use a decision table when the logic is best expressed as combinations of conditions. Use a decision tree when the logic is best expressed as a sequence of checks or a visual branch structure.
If your team wants a rule matrix, choose a table. If your team wants to trace decision paths, choose a tree. If the logic is stable and segmented, a table usually works well. If the logic is hierarchical, a tree usually communicates it better.
Use a decision table when:
- You need segmentation based on fixed attributes
- You want a lookup-style structure
- You need actuarial or pricing rules
- You want to list combinations explicitly
- You care about auditability and rule review
Use a decision tree when:
- You want to show the order of checks
- You need a visual explanation of the logic
- The decision process has clear branching steps
- You want teams to reason about paths, not rows
- The structure is hierarchical rather than tabular
A practical example
Imagine a lending decision.
A decision table might list combinations such as income band, employment status, and risk tier. Each row maps to approve, refer, or decline. That works well if the policy is based on predefined buckets.
A decision tree might start with income check, then employment check, then risk tier, then affordability. That works well if the underwriting flow has a natural sequence.
If you later add a new branch at one point in the tree, the table translation may need a new column or an extra combination of conditions. The logic still works, but the maintenance cost rises. That is why structure matters before implementation.
How this affects decision logic in practice
In real systems, decision logic changes over time. Rules are added. Thresholds move. Segments split. That means the format you choose affects long-term maintainability.
A decision table is often easier to govern when the business owns the rules and the number of variables stays manageable. A decision tree is often easier to explain when stakeholders care about the path of a single case.
In a platform like Decisimo, the best approach is usually to model decision logic in the form that matches the business problem first, then trace and test the equivalent representation if needed. The goal is not to force every rule into one shape. The goal is to keep the logic deterministic, explainable, and easy to audit.
Summary
Decision tables and decision trees can represent the same decision logic. A table is best for segmentation, lookups, and actuarial-style rules. A tree is best for visual segmentation and step-by-step reasoning.
If the branches are irregular, translating a tree into a table can make the logic wide and harder to manage. If the conditions are stable and combined in a predictable way, a table stays cleaner. Choose the structure that fits the shape of the decision, not the one that looks simpler at first glance.
That is the practical difference.